The Decision Support System (DSS) was introduced at very early days of computer and information systems, and thats continues till today.
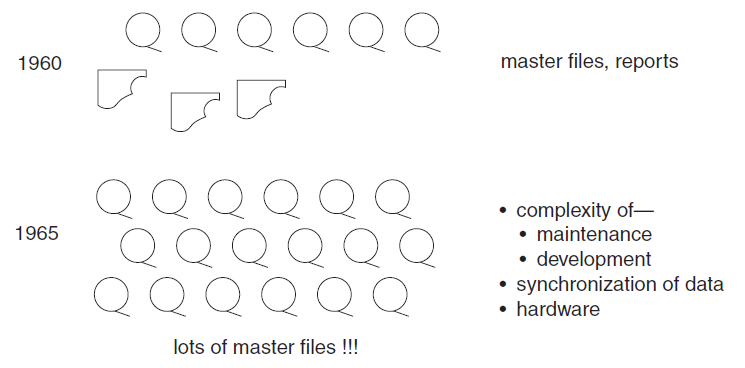
In the early 1960s, the world of computation consisted of creating individual applications that were run using master files. The master files were housed on magnetic tape, which were good for storing large volume of data cheaply, but the drawback was that they had to be accessed sequentially. In short order, the problems of master files—problems inherent to the medium itself—became stifling.

By 1970, the day of a new technology for the storage and access of data had dawned i.e. disk storage, or direct access storage device (DASD). Disk storage was fundamentally different from magnetic tape storage in that data could be accessed directly on DASD.
With DASD came a new type of system software known as a database management system (DBMS). The purpose of the DBMS was to make it easy for the programmer to store and access data on DASD. In addition, the DBMS took care of such tasks as storing data on DASD, indexing data, and so forth. With DASD and DBMS came a technological solution to the problems of master files. And with the DBMS came the notion of a “database.”

By the mid-1970s, online transaction processing (OLTP) made even faster access to data possible, opening whole new vistas for business and processing.
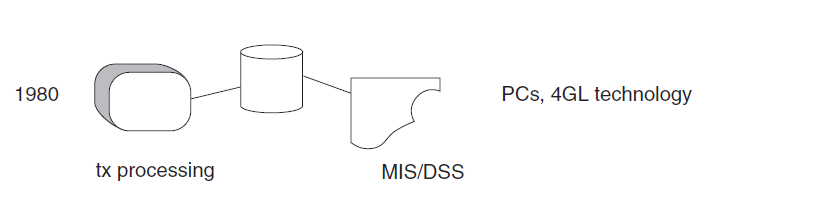
By the 1980s, more new technologies, such as PCs and fourth-generation languages (4GLs), began to surface. The end user began to assume a role previously unfathomed—directly controlling data and systems—a role previously reserved for the data processor. With PCs and 4GL technology came the notion that more could be done with data than simply processing online transactions.
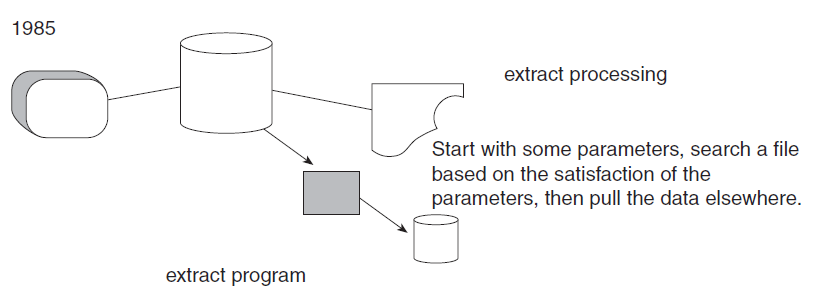
Shortly after the advent of massive OLTP systems, an innocuous program for “extract” processing began to appear. The extract program is the simplest of all programs. It rummages through a file or database, uses some criteria for selecting data, and, on finding qualified data, transports the data to another file or database.
The extract program became very popular, for at least two reasons:
- Because extract processing can move data out of the way of high performance online processing, there is no conflict in terms of performance when the data needs to be analyzed.
- When data is moved out of the operational, transaction-processing domain with an extract program, a shift in control of the data occurs. The end user then owns the data once he or she takes control of it. For these (and probably a host of other) reasons, extract processing was soon found everywhere.
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.