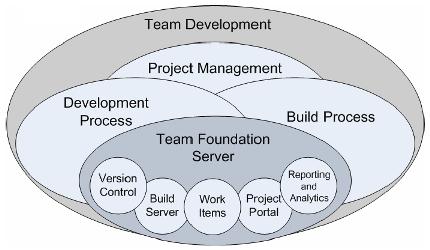
SQL Server is split into two main engines: the Relational Engine and the Storage engine.
The Relational Engine:
The relational Engine is also sometimes call the query processor because its primary function is query optimization and execution. It contains a Command Parser to check query syntax and prepare query trees, a Query Optimizer that is arguably the crown jewel of any database system, and a Query Executor responsible for execution.
1. Command Parser:
The Command Parser’s role is to handle T-SQL language events. It first checks the syntax and returns any errors back to the protocol layer to send to the client. If the syntax is valid, then the next step is to generate a query plan or find an existing plan. A Query plan contains the details about how SQL Server is going to execute a piece of code. It is commonly referred to as an execution plan.
Plan Cache: Creating execution plans can be time consuming and resource intensive, so The Plan Cache, part of SQL Server’s buffer pool, is used to store execution plans in case they are needed later.
2. Query Optimizer:
The Query Optimizer is one of the most complex and secretive parts of the product. It is what’s known as a “cost-based” optimizer, which means that it evaluates multiple ways to execute a query and then picks the method that it deems will have the lowest cost to execute. This “method” of executing is implemented as a query plan and is the output from the optimizer.
3. Query Executor:
The Query Executor’s job is self-explanatory; it executes the query. To be more specific, it executes the query plan by working through each step it contains and interacting with the Storage Engine to retrieve or modify data.
The Storage Engine:
The Storage engine is responsible for managing all I/O to the data, and contains the Access Methods code, which handles I/O requests for rows, indexes, pages, allocations and row versions, and a Buffer Manager, which deals with SQL Server’s main memory consumer, the buffer pool. It also contains a Transaction Manager, which handles the locking of data to maintain Isolation (ACID properties) and manages the transaction log.
1. Access Methods:
Access Methods is a collection of code that provides the storage structures for data and indexes as well as the interface through which data is retrieved and modified. It contains all the code to retrieve data but it doesn’t actually perform the operation itself; it passes the request to the Buffer Manager.
2. Buffer Manager:
The Buffer Manager manages the buffer pool, which represents the majority of SQL Server’s memory usage. If you need to read some rows from a page the
Buffer Manager will check the data cache in the buffer pool to see if it already has the page cached in memory. If the page is already cached, then the results are passed back to the Access Methods. If the page isn’t already in cache, then the Buffer Manager will get the page from the database on disk, put it in the data cache, and pass the results to the Access Methods.
Data Cache: The data cache is usually the largest part of the buffer pool; therefore, it’s the largest memory consumer within SQL Server. It is here that every data page that is read from disk is written to before being used.
3. Transaction Manager:
The Transaction Manager has two components that are of interest here: a Lock Manager and a Log Manager.
The Lock Manager is responsible for providing concurrency to the data, and it delivers the configured level of isolation by using locks. The Access Methods code requests that the changes it wants to make are logged, and the Log Manager writes the changes to the transaction log. This is called Write-Ahead Logging.
The Protocol Layer:
When the protocol layer in SQL Server receives your TDS (Tabular Data Stream) packet, it has to reverse the work of the SNI at the client and unwrap the packet to find out what request it contains. The protocol layer is also responsible for packaging up results and status messages to send back to the client as TDS messages.
TDS (Tabular Data Stream) Endpoints: TDS is a Microsoft-proprietary protocol originally designed by Sybase that is used to interact with a database server.