Extreme Programming (XP) is the most widely used agile methodology. XP is a discipline of software development based on values of simplicity, communication, feedback, and courage. It works by bringing the whole team together in the presence of simple practices, with enough feedback to enable the team to see where they are and to tune the practices to their unique situation.
In Extreme Programming, every contributor to the project is a member of the “Whole Team”, a single business/development/testing team that handles all aspects of the development. Central to the team is the “Customer”, one or more business representatives who sit with the team and work with them daily.
Extreme Programming teams use a simple form of planning and tracking to decide what to do next and to predict when any desired feature set will be delivered. Focused on business value, the team produces the software in a series of small fully integrated releases that pass all the
tests that the Customer has defined. The core XP practices for the above are called Whole Team, Planning Game, Small Releases, and Acceptance Tests.
Extreme Programmers work together in pairs and as a group, with simple design and obsessively tested code, improving the design continually to keep it always just right for the current needs. The core XP practices here are Pair Programming, Simple Design, Test-Driven
Development, and Design Improvement.
The Extreme Programming team keeps the system integrated and running all the time. The programmers write all production code in pairs, and all work together all the time. They code in a consistent style so that everyone can understand and improve all the code as needed. The additional practices here are called Continuous Integration, Team Code Ownership, and Coding Standard.
The Extreme Programming team shares a common and simple picture of what the system looks like. Everyone works at a pace that can be sustained indefinitely. These practices are called Metaphor, and Sustainable Pace.
In Extreme Programming, every contributor to the project is a member of the “Whole Team”, a single business/development/testing team that handles all aspects of the development. Central to the team is the “Customer”, one or more business representatives who sit with the team and work with them daily.
Extreme Programming teams use a simple form of planning and tracking to decide what to do next and to predict when any desired feature set will be delivered. Focused on business value, the team produces the software in a series of small fully integrated releases that pass all the
tests that the Customer has defined. The core XP practices for the above are called Whole Team, Planning Game, Small Releases, and Acceptance Tests.
Extreme Programmers work together in pairs and as a group, with simple design and obsessively tested code, improving the design continually to keep it always just right for the current needs. The core XP practices here are Pair Programming, Simple Design, Test-Driven
Development, and Design Improvement.
The Extreme Programming team keeps the system integrated and running all the time. The programmers write all production code in pairs, and all work together all the time. They code in a consistent style so that everyone can understand and improve all the code as needed. The additional practices here are called Continuous Integration, Team Code Ownership, and Coding Standard.
The Extreme Programming team shares a common and simple picture of what the system looks like. Everyone works at a pace that can be sustained indefinitely. These practices are called Metaphor, and Sustainable Pace.
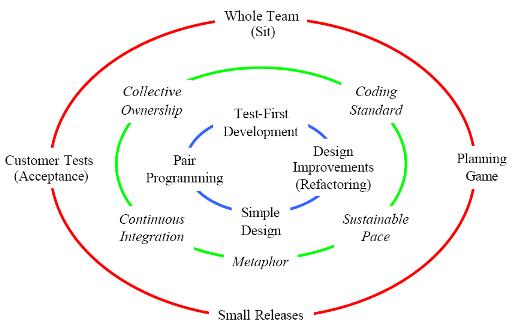
Fig : XP Practices and the Circle of Life





















